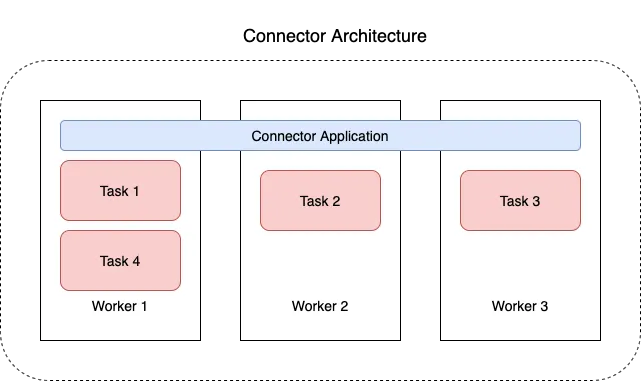
Kafka Connect
•
Kafka Connect 는 외부 시스템에 연결하기 위한 프레임워크를 제공하는 KAFKA 의 오픈 소스 구성 요소이다.
•
Kafka Connect 를 사용하기 위해서는 클러스터를 계획하고 프로비저닝하고, 작업을 처리하고 부하에 따라 스케일링을 고려해야 한다.
용어
•
Connect: Connector 를 동작하게 하는 프로세스 (서버)
•
Connector: Data Source(DB) 의 데이터를 처리하는 소스가 들어있는 jar 파일
•
Source Connector: Producer 역할을 담당
•
Sink Connector: Consumer 역할을 담당
•
Standalone 모드: 하나의 Connect 만 사용하는 모드
•
Distributed 모드: 여러개의 Connect 를 한개의 클러스터로 묶어서 사용하는 모드
◦
Connect 중 한개가 장애나도 나머지 Connect 들이 이어서 처리할 수 있음
설치 방법
•
직접 설치하는 방법도 있겠지만, 로컬에서 테스트로 필요하면 docker 로 띄울 수 있다
•
Guide
docker run -d \
--name=kafka-connect \
-e CONNECT_BOOTSTRAP_SERVERS=localhost:29092 \
-e CONNECT_REST_PORT=28083 \
-e CONNECT_GROUP_ID="quickstart-avro" \
-e CONNECT_CONFIG_STORAGE_TOPIC="quickstart-config" \
-e CONNECT_OFFSET_STORAGE_TOPIC="quickstart-offsets" \
-e CONNECT_STATUS_STORAGE_TOPIC="quickstart-status" \
-e CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_STATUS_STORAGE_REPLICATION_FACTOR=1 \
-e CONNECT_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_INTERNAL_KEY_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_INTERNAL_VALUE_CONVERTER="org.apache.kafka.connect.json.JsonConverter" \
-e CONNECT_REST_ADVERTISED_HOST_NAME="localhost" \
-e CONNECT_LOG4J_ROOT_LOGLEVEL=DEBUG \
-e CONNECT_PLUGIN_PATH=/usr/share/java,/etc/kafka-connect/jars \
-v /tmp/quickstart/file:/tmp/quickstart \
confluentinc/cp-kafka-connect:latest
Shell
복사
REST API
•
Kafka Connect 는 REST API 를 사용해서 Connector 를 만들 수 있는 방법을 제공한다
•
GET /connectors : 커넥터 목록 조회
•
GET /connectors/{name} : {name} 커넥터 정보 조회
•
GET /connectors/{name}/status : 커넥터 상태 조회
•
POST /connectors : 커넥터 생성
•
DELETE /connectors/{name} : {name} 커넥터 삭제
•
GET /connector-plugins : 설치된 플러그인 목록 조회
Debezium
•
데이터베이스의 변경 사항을 캡처하여 애플리케이션에서 사용할 수 있도록 해주는 분산 서비스 집합이다.
•
CDC ( Change Data Capture ) 을 사용하여 데이터베이스의 변경 사항을 수집한다
•
모든 Low Level 변경을 Changed Event Stream 에 기록한다.
◦
애플리케이션은 이 스트림을 통해 변경 이벤트들을 순서대로 읽는다
•
Debezium 의 목표는 다양한 DBMS 들의 변경 사항을 캡처하고 비슷한 구조의 변경 이벤트들을 Producing 하는 Connector 라이브러리를 구축하는것이다.
지원하는 커넥터
•
MySQL
•
MongoDB
•
PostgreSQL
•
Orcal
•
SQL Server
•
DB2
•
Cassandra
•
Vitess
특징
•
Debezium 은 Log Based CDC 이다.
•
모든 데이터 변경이 캡처된다
•
Data Model 변경이 필요 없다
•
변경 뿐만 아니라 삭제도 캡처한다
•
레코드의 과거 상태도 캡처가 가능하다.
기능
•
Snapshots: 커넥터가 시작될 때 데이터베이스의 현재 상태에 대한 초기 스냅샷을 생성할 수 있다.
•
Filters: 특정 테이블이나 컬럼의 변경만 캡처할 수 있다
•
Masking: 민감한 정보의 경우 특정 컬럼을 마스킹처리 할 수 있다
•
Message Transformation
◦
Topic Routing
▪
이 기능을 사용하면 토픽의 이름을 변경하거나, 여러개의 테이블의 변경사항을 하나의 토픽으로 전달할 수 있다
◦
New Record State Extraction
◦
Outbox Event Router
◦
Message Filtering
◦
Content-Based Routing
아키텍처
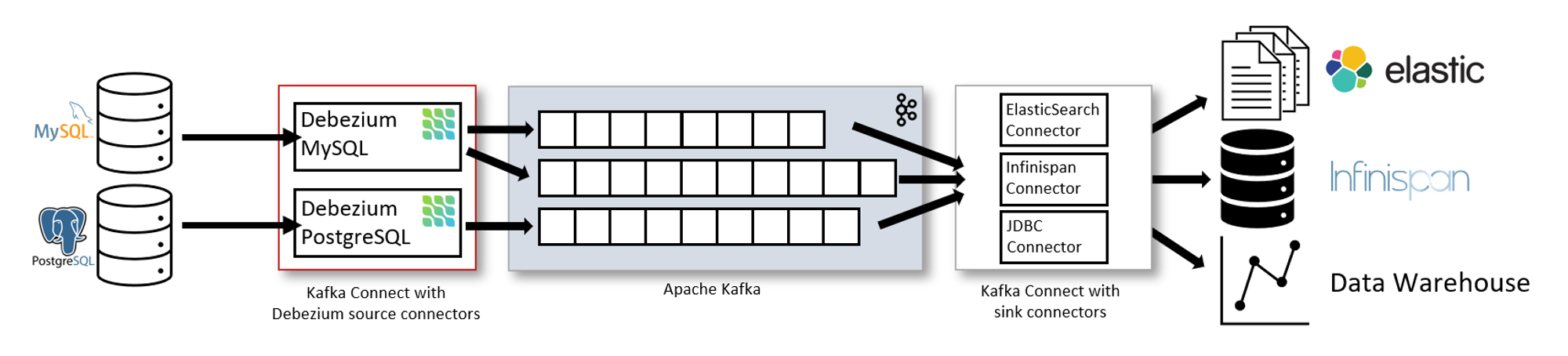
Kafka Connect
•
Kafka Connect 는 Kafka Broker 와 별도의 서비스로 운영된다
•
기본적으로 한 테이블의 변경 사항은 하나의 토픽으로 전달된다
•
MySQL 의 경우 binlog 에 접근하여 데이터를 가져온다
•
PostgreSQL 의 경우 Logical Replication Stream 에서 데이터를 가져온다
•
Source Connector 에서 가져온 정보들을 Sink Connector 를 통해서 ElasticSearch, Redis, Data Warehouse 등에 반영할 수 있다.
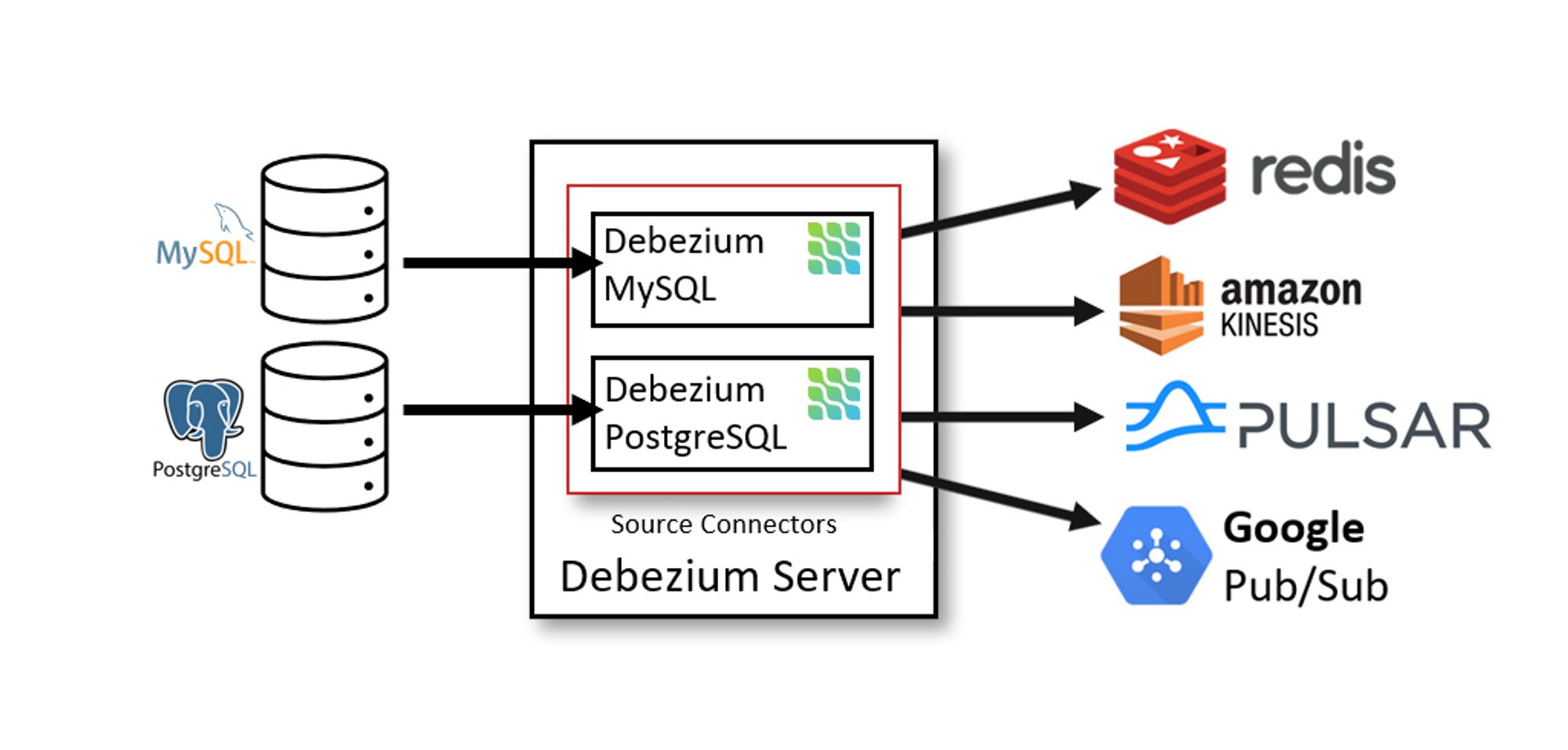
Debezium Server
•
•
Debezium Server 는 Source Connector 중 하나를 사용하여 Source Database 의 변경 사항을 캡처하도록 구성한다.
•
변경된 이벤트는 JSON, Apache Avro 와 같은 형식으로 직렬화 할 수 있으며 Kinesis, Google Pub/Sub, Redis 등에 메시지를 전달할 수 있다
Embedded Engine
•
Kafka Connect 를 사용하지 않고 Embedded Engine 을 사용하여 자바 애플리케이션 라이브러리로도 사용할 수 있다.
◦
Embedded Engine 은 변경 이벤트를 애플리케이션에서 바로 Consuming 하거나 변경 내역을 별도의 메시지 브로커(e.g Amazon Kinesis) 에 전달할 때 유용하다.
로그 기반의 CDC 의 장점
1.
모든 데이터를 캡처할 수 있다
•
로그 기반으로 데이터의 변경사항을 가져오게되면 애플리케이션에서는 정확한 순서대로 데이터의 변화를 감지할 수 있다.
•
폴링 기반의 데이터 변경 사항을 가져오게 될 경우 최신 데이터만 가져오게 되며, 다운타임이 발생 했을 때는 데이터를 못가져온다.
2.
CPU 부하가 적고, 지연 시간이 적다
•
쿼리를 주기적으로 요청하지 않아도 되기 때문에 CPU를 거의 사용하지 하지 않으며, 실시간에 가까운 데이터 변경에 대응할 수 있다.
3.
데이터 모델에 영향이 없다
•
폴링 기반의 CDC 는 마지막 폴링 이후 변경된 레코드를 식별하기 위해 LAST_UPDATE_TIMESTAMP 와 같은 정보들을 추가해야되지만, 로그 기반의 CDC 는 그런게 필요 없다.
4.
삭제된 데이터를 캡처할 수 있다.
5.
이전 레코드의 상태와 메타 데이터를 캡처할 수 있다
•
데이터가 업데이트 되었을 때, 이전 상태의 레코드 상태를 가져올 수 있다
•
로그 기반 CDC 는 Schema Change Stream 을 제공하고 Transaction ID 또는 사용자가 특정 변경사항을 적용한 것과 같은 메타데이터를 가져올 수 있다.
사용 방법
MSK Connector
•
MSK Connector 는 Kafka Connect 를 좀 더 쉽게 사용할 수 있는 기능을 제공한다.
•
21.02.18 기준으로 Kafka Connect 2.7.1 버전을 사용하고 있다
제공하는 기능
•
커넥터의 전송 상태 모니터링
•
하드웨어 패치
•
처량 변화에 맞춘 오토 스케일링
•
Kafka Connect 와 완벽한 호환 제공
•
MSK 외에 On-Demand Kafka Cluster 지원
•
그 외 사용하기 손쉽게 만들어주는 완전 관리형 서비스